
An overview of top Large Language Model (LLM) leaderboards to help you select the right LLM for your Generative AI project .
There are multiple aspects to choosing an LLM, however, an important step is to look at the popular leaderboards to see how the LLMs compare with each other. Ideally, you would want to do the comparison for your own task using your own dataset. However, that is not always easy. Let’s look at the popular LLM leaderboards and how those leaderboards are made.
HuggingFace Open LLM Leaderboard
The Open LLM Leaderboard by HuggingFace is probably the most popular leaderboard and has the following characteristics
- It covers tasks such as knowledge testing, reasoning on short and long contexts , complex mathematical abilities, and tasks well correlated with human preference, like instruction following.
- It covers the following six benchmarks – MMLU-Pro (Massive Multitask Language Understanding – Pro version), GPQA (Google-Proof Q&A Benchmark) , MuSR (Multistep Soft Reasoning) , MATH (Mathematics Aptitude Test of Heuristics), IFEval (Instruction Following Evaluation) and BBH (Big Bench Hard)
- The selection of the benchmarks were based on evaluation quality, Reliability and fairness of metric, General absence of contamination in models as of today and Measuring model skills that are interesting for the community
It uses EleutherAI’s evaluation harness to evaluate the LLMs. More details on the leaderboard criteria can be found here.

Chatbot Arena LLM Leaderboard
Researchers at UC Berkeley SkyLab and LMSYS developed the Chatbot Arena (https://lmarena.ai/) as an open source platform. It uses human preference alignment for its benchmark. It uses crowdsourcing and has collected around 2.1 million human votes. The way it works is this: you ask a question to two anonymous AI chatbots. You chose the best response and keep on doing that until you find a winner.
AlpacaEval Leaderboard
AlpacaEval uses automatic evaluation to evaluate instruction following models. It is validated against 20K human annotations. It is a quick method to evaluate models without collecting human feedback, however where accuracy is required human evaluation should be preferred. It provides four things – A leaderboard, an automatic evaluator , a Toolkit for building automatic evaluators and Human evaluation dataset.
Berkeley Function-Calling Leaderboard
This leaderboard evaluates the LLM’s accuracy in calling functions . It contains real world data that is updated periodically. Here’s an example of its comparison
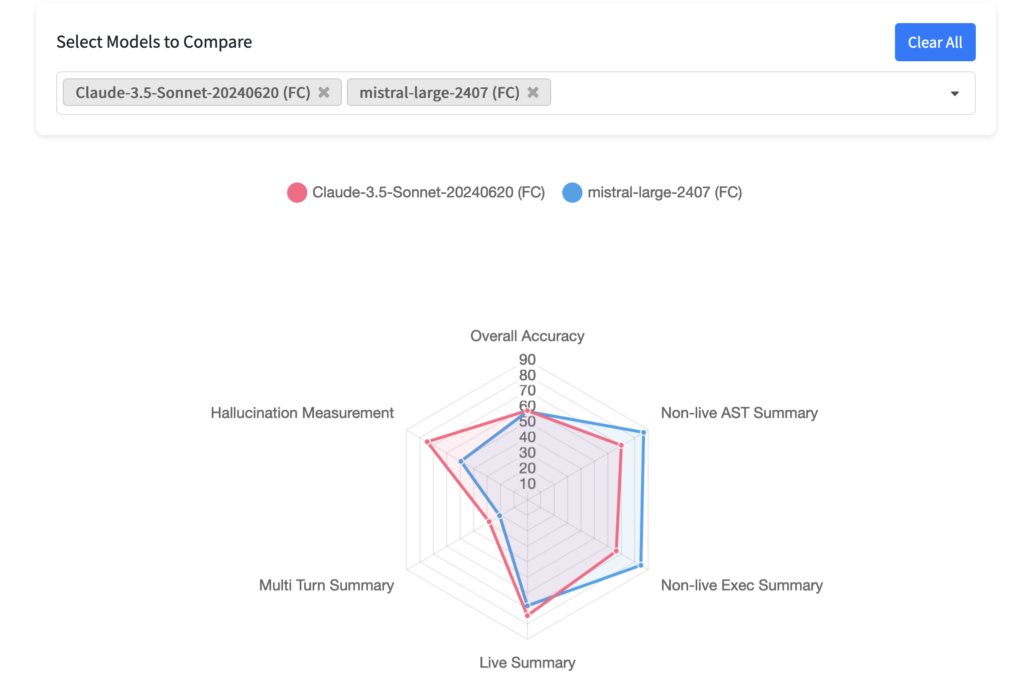
In addition to single turn conversations, it also evaluates multi step and multi turn conversations.
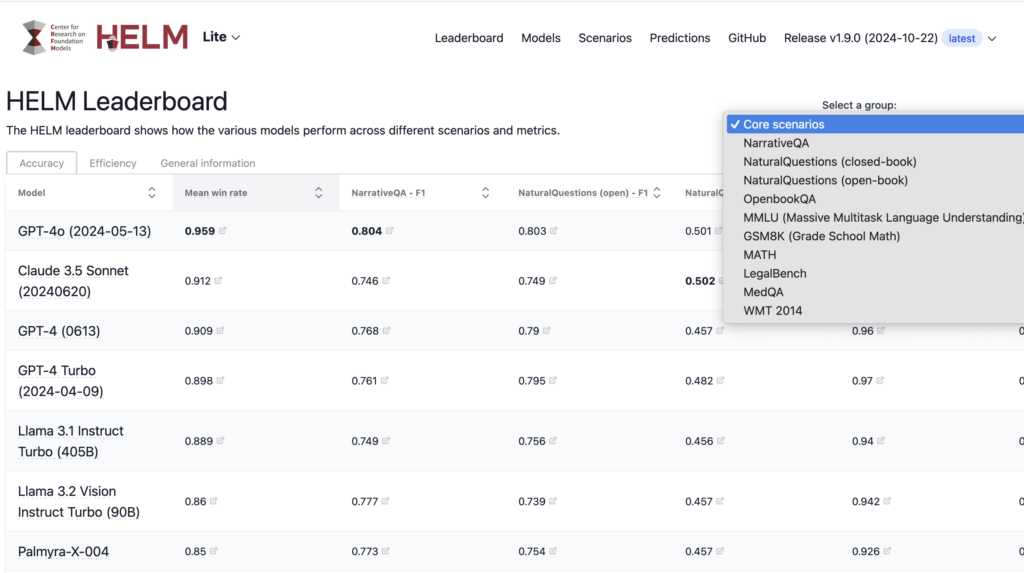
HELM
HELM stands for Holistic evaluation of Language models and is an evaluation framework by Stanford. It compares multiple models using multiple scenarios using multiple metrics. It is not a single leaderboard, but is composed of multiple specialized leaderboards such as HELM lite and classic, HEIM (text to image), HELM instruct, VHELM (Vision language) etc.
For example, HELM classic compares 142 models using 87 scenarios such as Question Answering, Information retrieval, Reasoning etc and metrics such as Accuracy, Callibration, Robustness, fairness, efficiency etc.
OpenCompass CompassRank
CompassRank is based on the closed source benchmark by OpenCompass. The benchmarks and leaderboard are updated every two months.
Leave a Reply